
Prometheus is an open-source and scalable monitoring and alerting framework, that generally works alongside Kubernetes (but not only). Configuring and operating Prometheus can be a bit of challenge due to its complexity, but past the learning curve and with proper patience, it is a really powerful tool for which no real alternative exists. Community Helm chart and official Manifests do a great job at hidding the inherent complexity of Prometheus and templating its configuration files. In this article, I will walk you through deploying it alongside Grafana.
feel free to share this article or drop a message with your feedback!
If you are a french speaker and want to learn Kubernetes, I highly recommend Stéphane Robert's website.
Prerequisites
You will need to have a Kubernetes cluster, and if you don't have one, check my tutorial on how to run Kubernetes in Vagrant.
Prometheus require the Kubelet to have the following configuration:
--authentication-token-webhook=true--authorization-mode=WebhookIt should be enabled by default in k3s. You can always check the values for these flags with the following commands on the node (will only work as root and with k3s):
journalctl -u k3s | grep 'Running kubelet' | tail -n1 | grep 'webhook'
journalctl -u k3s | grep 'Running kubelet' | tail -n1 | grep 'Webhook'
For your information, a Kubelet is a Kubernetes component that orchestrates pod (and containers) execution, manages resources, ensures cluster health, and facilitates communication between nodes and the control plane.
Installing the helm chart
Install the repository and the chart:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
kubectl create namespace monitoring
helm install -n monitoring prometheus prometheus-community/kube-prometheus-stack
You might get this error on first launch:
➜ helm install -n monitoring prometheus prometheus-community/kube-prometheus-stack
WARNING: Kubernetes configuration file is group-readable. This is insecure. Location: k3s.yaml
WARNING: Kubernetes configuration file is world-readable. This is insecure. Location: k3s.yaml
Error: INSTALLATION FAILED: unable to build kubernetes objects from release manifest: [resource mapping not found for name: "prometheus-kube-prometheus-alertmanager" namespace: "monitoring" from "": no matches for kind "Alertmanager" in version "monitoring.coreos.com/v1"
ensure CRDs are installed first, resource mapping not found for name: "prometheus-kube-prometheus-prometheus" namespace: "monitoring" from "": no matches for kind "Prometheus" in version "monitoring.coreos.com/v1"
ensure CRDs are installed first, resource mapping not found for name: "prometheus-kube-prometheus-alertmanager.rules" namespace: "monitoring" from "": no matches for kind "PrometheusRule" in version "monitoring.coreos.com/v1"
This a race condition due to CRD manifest being applied and the custom Prometheus resources not yet being available, you can simply relaunch the command.
Configuring the Helm chart
Helm charts are configured through their values.yaml file.
If you run ``, you will see the content of this file for your
deployment, and that no user supplied values were passed.
The chart default values, with comment serving as documentation,
can be downloaded with the following command:
helm show values prometheus-community/kube-prometheus-stack > default_values.yaml
You are then free to navigate the file and customize the deployment. This section will walk you through changes I think are important.
Grafana and its Ingress
You first need to ensure, if your ingress controller is not configure to default to
a specific secret, that the tls secret is available in the new monitoring namespace.
If your tls secret exists in the default namespace under the name certif-secret, you can copy
it with the following command:
kubectl get secret certif-secret -n default -o yaml | sed "s/namespace: default/namespace: monitoring/g" | kubectl apply --namespace=monitoring -f -
Then, enable and configure the ingress for grafana, as well as its storage in a new prom-values.yaml file:
grafana:
enabled: true
## Deploy default dashboards
defaultDashboardsEnabled: true
## Timezone for the default dashboards
## Other options are: browser or a specific timezone, i.e. Europe/Luxembourg
defaultDashboardsTimezone: browser
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: traefik
annotations:
traefik.ingress.kubernetes.io/frontend-entry-points: https
traefik.ingress.kubernetes.io/redirect-entry-point: https
traefik.ingress.kubernetes.io/redirect-permanent: "true"
hosts:
- monitoring.demo-cluster.io
path: /
tls:
- hosts: ["monitoring.demo-cluster.io"]
secretName: certif-secret
persistence:
enabled: true
storageClassName: ""
accessModes:
- ReadWriteOnce
size: 3Gi
Note that we use the default storage class. Tune this file to your needs. You will
also need to add an entry for monitoring.demo-cluster.io to your /etc/hosts
or DNS server.
In the tutorial where we create the cluster, I've mentioned the risk of exposing your k3s to an interface that is facing internet. This chart is a great example of catastrophic consequences of having the default password value here exposing a Grafana instance with default password to the entire world. Beware!
Easier time with ServiceMonitor
This helm charts defaults to values where you are required to add annotations matching the helm chart on all ServiceMonitor, PodMonitor and other Monitor resources you want Prometheus to scrap. This is verbose, and a bit overkill in my opinion, as most manifests you will get for these resources will likely not include any annotation. It creates room for configuration errors so I generally disable it this way:
prometheus:
prometheusSpec:
## If true, a nil or {} value for prometheus.prometheusSpec.podMonitorSelector will cause the
## prometheus resource to be created with selectors based on values in the helm deployment,
## which will also match the podmonitors created
##
podMonitorSelectorNilUsesHelmValues: false
## If true, a nil or {} value for prometheus.prometheusSpec.probeSelector will cause the
## prometheus resource to be created with selectors based on values in the helm deployment,
## which will also match the probes created
##
probeSelectorNilUsesHelmValues: false
## If true, a nil or {} value for prometheus.prometheusSpec.scrapeConfigSelector will cause the
## prometheus resource to be created with selectors based on values in the helm deployment,
## which will also match the scrapeConfigs created
##
scrapeConfigSelectorNilUsesHelmValues: false
## If true, a nil or {} value for prometheus.prometheusSpec.serviceMonitorSelector will cause the
## prometheus resource to be created with selectors based on values in the helm deployment,
## which will also match the servicemonitors created
##
serviceMonitorSelectorNilUsesHelmValues: false
deploying Grafana
You should now be able to apply your manifest the following way:
helm upgrade -n monitoring prometheus prometheus-community/kube-prometheus-stack -f prom-values.yaml
After that, you should be able to access monitoring.demo-cluster.io in your web browser
with the following credentials:
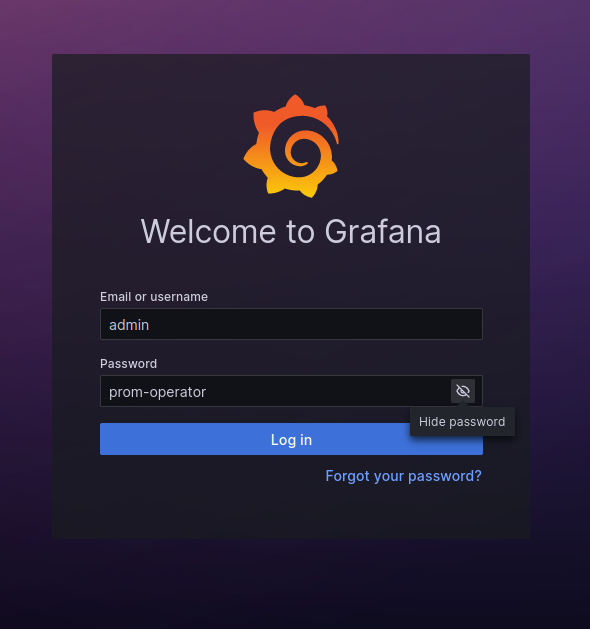
In the dashboard section of the collapsable panel to the right, you have a list of dashboards to monitor pretty much everything in your cluster (CPU, RAM, per Pod, per Namespace...).
Spread the word
If you liked this article, feel free to share it on LinkedIn, send it to your friends, or review it. It really make it worth my time to have a larger audience, and it encourages me to share more tips and tricks. You are also welcome to report any error, share your feedback or drop a message to say hi!