
This post is an attempt at sharing what I learnt the hard way while writing my firsts high throughput Numaflow pipelines. It took me some time to convince myself that I had a resource efficient and safe pipeline, and I had to troubleshoot a few misconfiguration errors I made.
feel free to share this article or drop a message with your feedback!
Introduction: What's Numaflow ?
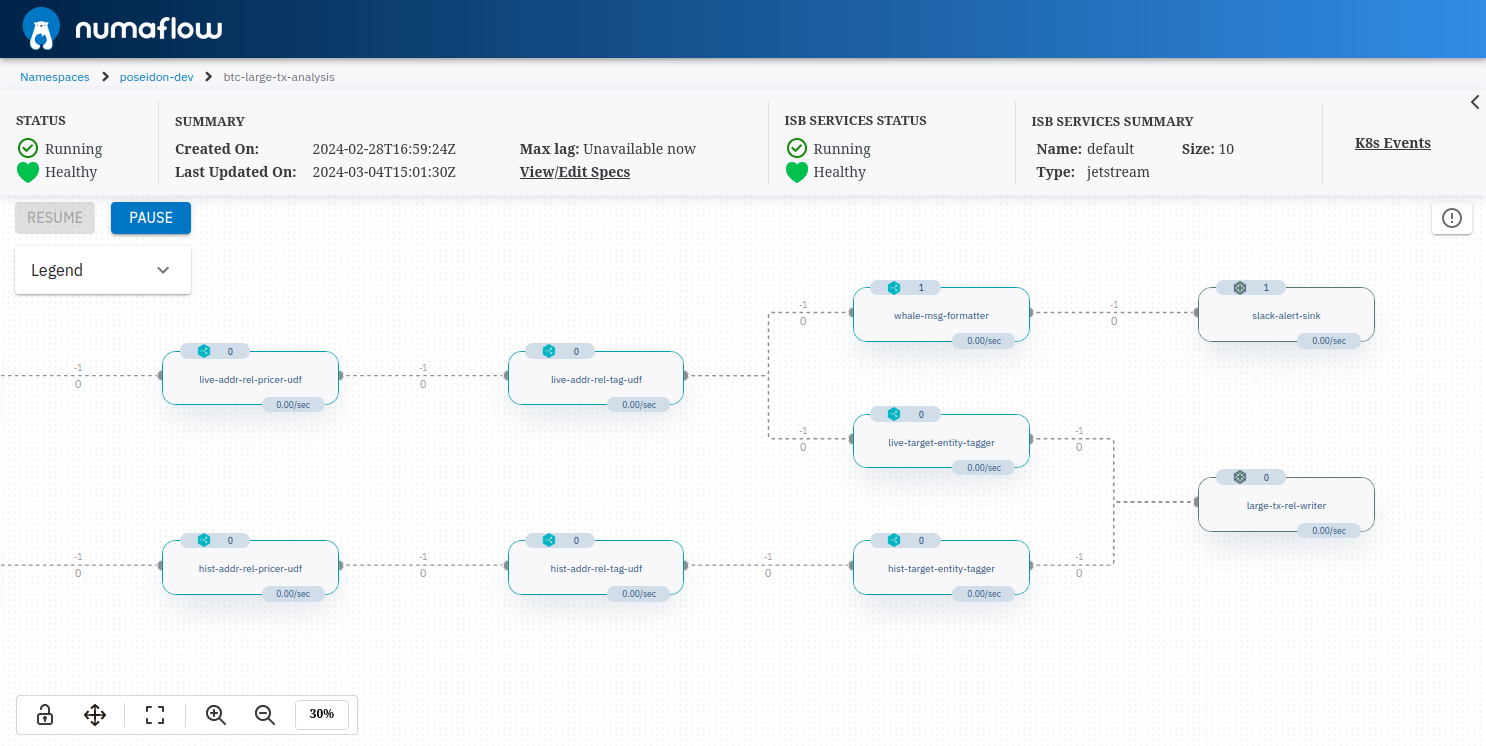
If you're not familiar with Numaflow, visit their excellent documentation. To summarize, it is a scalable and event oriented framework for data pipelines built into Kubernetes using custom resources and an operator. It also has a convenient web app. To create a pipeline, you define it as a YAML that most notably contains a set of vertices that are either sources, processors, or sinks and can be built in or user defined. To communicate between vertices, you define edges that use underlying streams, generally powered by a Jetstream managed as a Inter Step Buffer Service resource in Kubernetes. The data flows between steps and can be filtered at edges. Once again, for more details, visit the Numaflow documentation.
TIP 1: Partitionning
Numaflow defaults to a single partition per inter step buffer (edge). It is convenient
for small workloads, but for more than 5 thousands messages per second, you will need
to use partitioning. As far as I understand, you're better off having too much partition
than too little, so it's a good rule of thumb to use at least 4 or 5 partitions if you know
that some edge can receive a few thousands messages per second. This can be achieve by setting
the partition key of the vertice that is reading the buffer, which "owns" edge:
- name: live-addr-rel-pricer-udf
partitions: 4 # <- it happens here
udf:
container:
image: registry.gitlab.com/my-company/my-repo/message-enriching-udf:v1.56.0
env:
- name: MY_ENVAR
value: "My value"
imagePullSecrets:
- name: registry-credentials
TIP 2: Finding the right jetstream settings
I made today a Pull Request to revive the Redis ISBSVC (that was not usable anymore due to a bug). It lacks the following features as of 15th of March 2024:
- Watermark
- Reduce processors
- Side inputs
- Transformers
Jetstream, as opposed to Redis, ensures high availability, scalability, and that no datum can be lost after the request to write has returned. This is achieved by using a NATS optimized RAFT algorithm for clustering, replicating all data, and using disk persistence. This comes with a significant overhead, and the default settings in Numaflow with 3 replicas will be less performant (but in theory safer) than a single instance of Redis, which primarly functions with RAM (but can persist as well). Depending on your use case, tweaking the configuration of Jetstream might be necessary.
Providing sufficient replicas
For a pipeline with a few thousands of messages per seconds on some edges over a small dozen of vertices,
you might need more than the default 3 replicas if your replication factor is not 1 or that you do not
function in RAM-only mode. If you have one disk per replica, you might also benefit scaling up to more disks to avoid reaching the disks IOPS bottleneck. This achieved with the spec.jetstream.replicas field of the inter step buffer service manifest:
apiVersion: numaflow.numaproj.io/v1alpha1
kind: InterStepBufferService
metadata:
name: default
namespace: my-namespace
spec:
jetstream:
version: 2.10.3
replicas: 10 # <- this key
Tuning retention policy and max memory
Jetstream support three retention policies: Limits, Interest and WorkQueue.
You can read more on this documentation page.
By default, it will use the Limits policy, which keeps messages even
after they were readed and acked. This can lead to a higher resource usage than necessary,
especially if the memory limit is high, and I got satisfying saving by switching
to WorkQueue.
This setting is achieved by setting the retention key of the bufferConfig string:
apiVersion: numaflow.numaproj.io/v1alpha1
kind: InterStepBufferService
metadata:
name: default
namespace: my-namespace
spec:
jetstream:
version: 2.10.3
replicas: 10
bufferConfig: |
# The properties of the buffers (streams) to be created in this JetStream service
stream:
# 0: Limits, 1: Interest, 2: WorkQueue
retention: 2 # <- here
Setting limits
You need to ensure that your limit for the maximum payload is sufficient for your expected message size (or treat large message separately), otherwise your pipeline will stall. You'd also better make sure it's small enough so that you're not wasting resources on skewed messages. You then need to set a reasonable RAM limit for Jetstream. Both settings are demonstrated here:
apiVersion: numaflow.numaproj.io/v1alpha1
kind: InterStepBufferService
metadata:
name: default
namespace: my-namespace
spec:
jetstream:
version: 2.10.3
replicas: 10
settings: |
max_payload: 8388608
max_memory_store: 8073741824
The Jetstream pods logs in Kubernetes show these settings when starting, as well as other interesting things.
Lowering the safety of your messaging
Your pipeline may have the following properties:
- All vertices are idempotent (a duplicate message has no consequence).
- All sources have an offset, and can return to a previous one when recreating the pipeline.
- A rare downtime or delay can be tolerated.
If your pipeline safety is not critical, or if the 3 previous conditions are met, you might be
relatively safe switching to RAM only mode (escaping the disk IO bottlenecks), and lowering the
data replication factor the following way with the storage and replicas settings:
apiVersion: numaflow.numaproj.io/v1alpha1
kind: InterStepBufferService
metadata:
name: default
namespace: my-namespace
spec:
jetstream:
version: 2.10.3
replicas: 10
settings: |
max_payload: 8388608
max_memory_store: 8073741824
bufferConfig: >
stream:
# 0: Limits, 1: Interest, 2: WorkQueue
retention: 2
maxMsgs: 30000
maxAge: 24h
maxBytes: -1
# 0: File, 1: Memory
storage: 1 ### <- this switch to RAM only mode
replicas: 1 ### <- this does not replicate data in the streams
duplicates: 15m
otBucket:
maxValueSize: 0
history: 1
ttl: 24h
maxBytes: 0
storage: 1 ### <- this switch to RAM only mode
replicas: 1 ### <- this does not replicate data
procBucket:
maxValueSize: 0
history: 1
ttl: 24h
maxBytes: 0
storage: 1 ### <- this switch to RAM only mode
replicas: 1 ### <- this does not replicate data
The risk of doing that is that multiple Jetstream replicas can crash or disconnect, in the occurence for example
of all replicas that hold the replication of a stream being on a node while it is out of memory. In that eventuality, the
stream will be lost with a message that is akin to unable to find stream in the Numaflow containers that
are reading/writing this edge. This might be unlikely but in that eventuality, having an idempotent pipeline
where you can pick the start offset allows you to simply recreate the pipeline at lower offset without any data loss.
The otBucket and procBucket seems to do very little disk I/O. I observed one read per replica per second. Though, if your streams are not persisted, there is little interest in persisting only these buckets.
Watching the network bandwidth and locality
Jetstream and Numaflow relies heavily on communication between containers. Reaching the maximum network throughput at your disposal is likely if you're in a high throughput scenario. Watch out for these metrics and for timeout errors.
TIP 3: User defined vertices reusability is your ennemy
When I first started making pipelines, I was really enthusiast at how easilly I could reuse some User Defined Functions processors in related but different pipelines. I quickly noticed after reusing generic Processors that it meant passing more messages than it should. For example, having a Flatmap processor with a high output to input ratio followed by a filter really doesn't make sense from a performance perspective as you can (depending on your filtering rate) save most of the disk I/O (assuming you use persisted Jetstreams) by merging those two UDF processors in one.
So I'd strongly recommend factoring out all of the UDF logic into libraries that can be reused inside specialized UDF, rather than combining general purpose UDF to do specialized tasks.
TIP 4: Watch for the batch size
Depending on your map UDF use cases, you will need to choose between a regular map that processed mini batches, or a streaming map that will pass messages one by one. While the streaming one is good for long processing times or to stay below maximum gRPC message size, passing all messages one by one has a tremendous overhead, as this flame graph of the go sdk can attest (despsite a high number of goroutines on my Map, most of the procesing time is spent out of it):
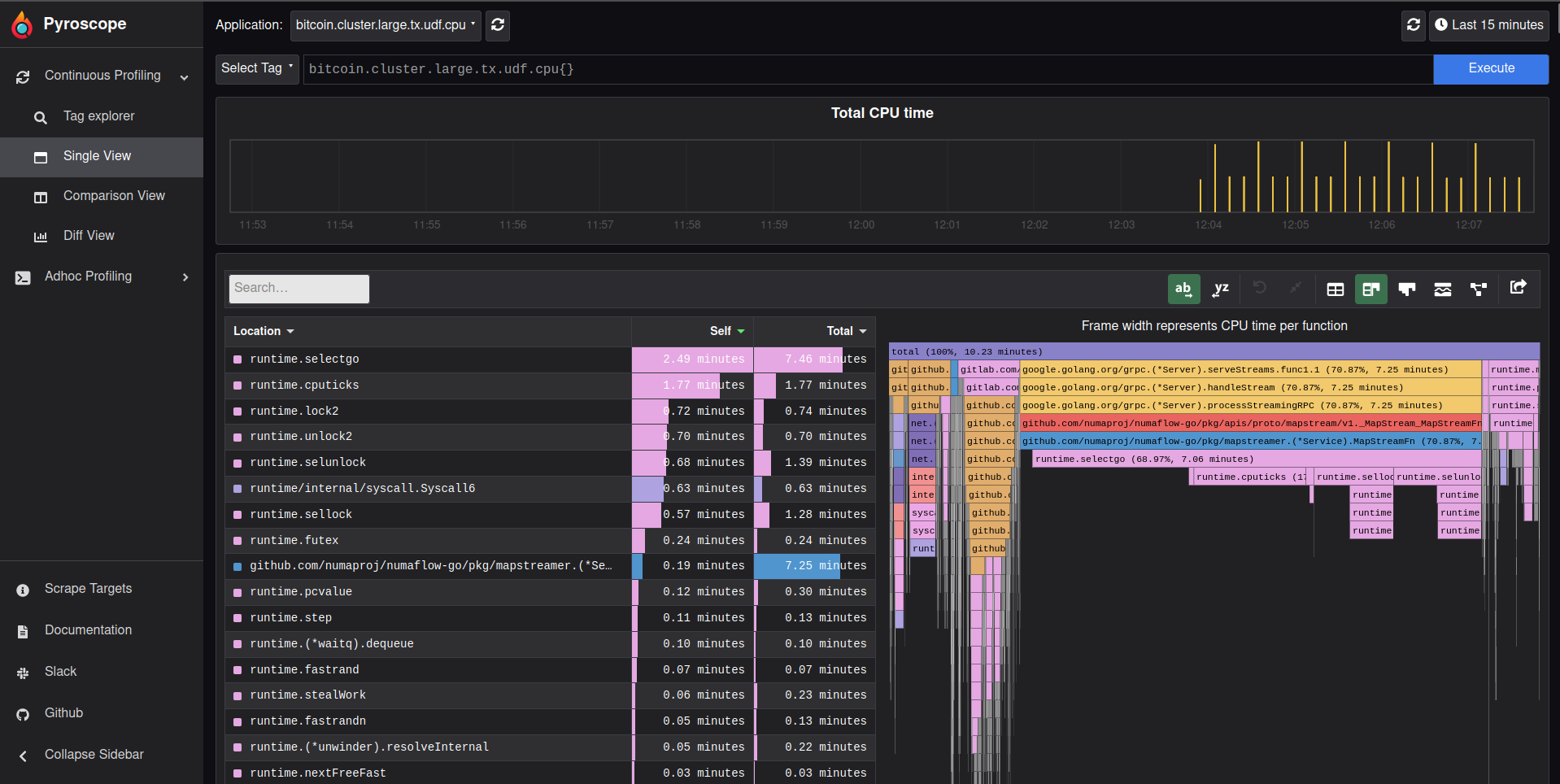
If you go for the regular map, you will need to tune the batch size to your use case with
the limits values of the vertices manifest (generally in the pipeline manifest). Note that the Numaflow team benchmarked some of these values to choose reasonable defaults.
- name: live-addr-rel-pricer-udf
partitions: 4 # <- it happens here
udf:
container:
image: registry.gitlab.com/my-company/my-repo/message-enriching-udf:v1.56.0
env:
- name: MY_ENVAR
value: "My value"
imagePullSecrets:
- name: registry-credentials
scale:
max: 5
limits:
readBatchSize: 64 # <- this is the batch size
bufferMaxLength: 10000 # <- this is the max number of messages that can be stored by the buffer we read from
Just like with Spark, having a special treatment for outliers in skewed datasets can be of great help to maximize throughput.
TIP 5: Deploy the right tracing and monitoring utilities
When it comes to data ops, you are just as good as you can observe, and Numaflow is not an exception. You will greatly benefit from integrating these utilities into your workflow. I'd actually argue that some are mandatory.
Prometheus with Grafana
The Numaflow team provides a sample grafana dashboard
and integrates well with Prometheus. You will benefit from using their ServiceMonitor to scrap
the metrics off the pipeline and isbsvc pods.
Apart from the Numaflow metrics, you should really keep an eye on your cluster's monitoring when first running pipelines. A misconfigured Jetstream or an aggresively scaling pipeline might impact other Kubernetes resources through shared bottleneck (like networking), or impact cost.
Log management with ELK
A pipeline with a dozen of vertices and a few Jetsream replicas might generate a lot of logs at various places. You might want to delve into advanced log management and custom dashboards to catch errors more easilly. The Elasticsearch Logstash Kibana stack is great for that and your workflow will benefit from this increased productivity. The Numaflow logs are also JSON and can be parsed easilly.
Tracing
Depending on your language of choice and habits, you might have your own favourite tools for performance profiling, tracing and debugging. What I personnally enjoy is to deploy Pyroscope and when needed, let the UDF send their stack to the webapp.
Bonus: Segregate your ISBSVC.
I have to admit I've had a terrible first experience operating and configuring bare metal Jetsream clusters. It felt easy to make a mistake and blow up the house. I'm getting more confident now and I enjoy the support of the Numaflow team, that operates Jetstream with Numaflow in production and has the kindness to share their experience and help, for which I am gratefull. I suspect it might be a good idea not to use a single ISBSVC for all your production pipelines, or even development ones, to prevent one pipeline from influencing another. Numaflow allows to define multiple ISBSVC and to pick one in the pipeline manifest.
Spread the word
If you liked this article, feel free to share it on LinkedIn, send it to your friends, or review it. It really make it worth my time to have a larger audience, and it encourages me to share more tips and tricks. You are also welcome to report any error, share your feedback or drop a message to say hi!