
One of the biggest challenge of designing Spark transformations is handling skewed datasets. Depending on your database schema and driver, you might be pulling this data already skewed, and you might also need to order it based on columns that are inherently skewed. In this article, after a brief explanation on how to identify skews, I dive into mitigation strategies for ordering over skewed window.
feel free to share this article or drop a message with your feedback!
About skewness
We will define skewness in spark as the uneven balancing of data during processing or storage. It typically creates uneven processing time for tasks. A possible consequence of that is that as job tasks are dispatched between executors and cores, a job with a finite number of tasks will see a minority of executors running for much longer than the rest, effectively leaving all remaining cores idle untill all jobs tasks are completed. A severe skew can easilly waste 90% of processing power, and you might also be at risk of running into memory issues as the large jobs requires more RAM. A typical pitfall is to scale the executors up to be able to handle these minorities of large task rather than ensuring they are evenly balanced.
How to tell if our spark jobs are skewed ?
Spark actually makes it pretty easy. In the Spark web UI, you can see for each Spark data transformation the list of Stages, which contains the list of Jobs, which contains the list of Tasks. Spark also provide quantiles for the tasks input, output size, and processing time. One can also sort the list of tasks by processing time and see if there exists tasks that took suspiciously long.
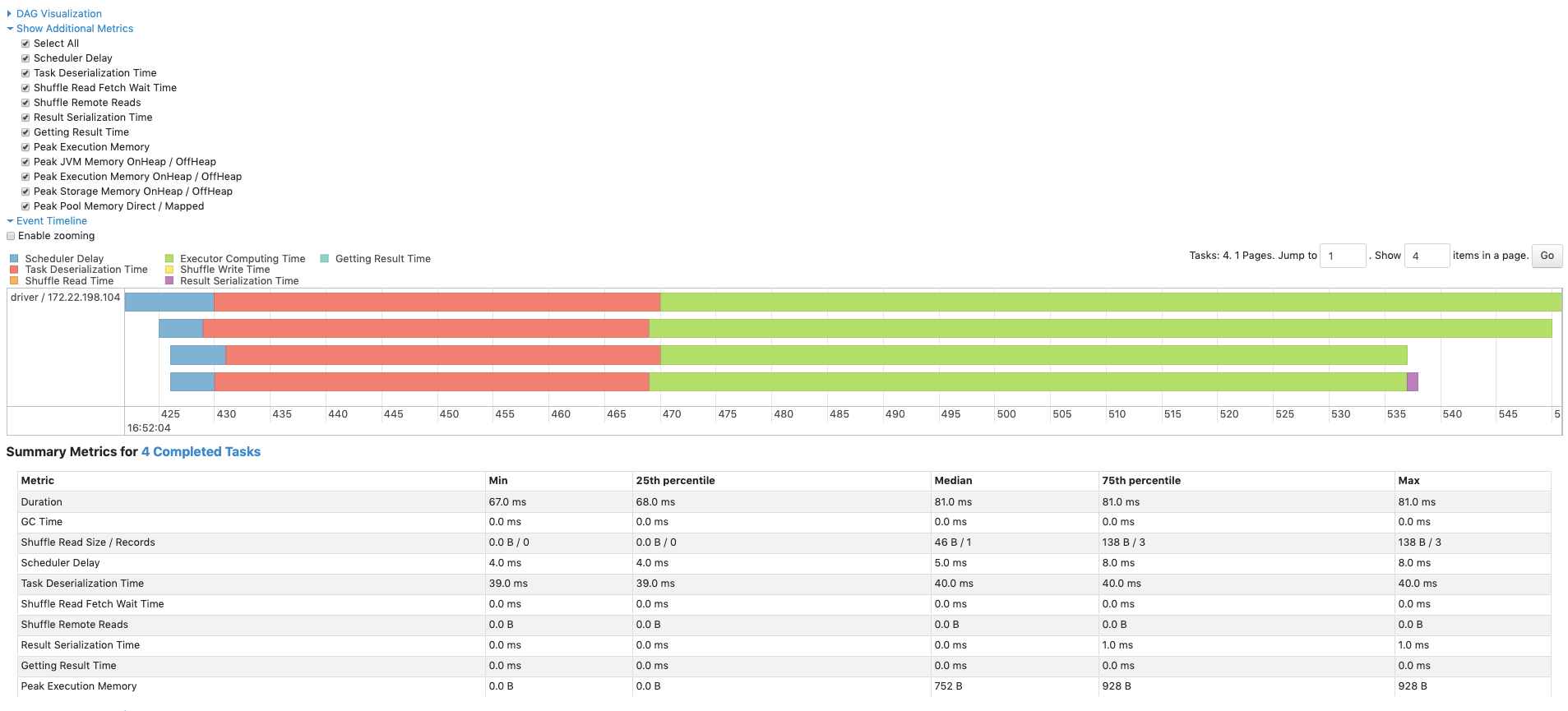
One last symptom of skewed spark jobs is sharp drops of CPU usage in the spark executors monitoring metrics, with a very low level being reached near the end of stage's jobs. CPU usage changes can also be due by I/O throttling, so we should not consider that there exist a bijection between skewness and uneven CPU usage.
An example of skewed tasks
Let's suppose we are looking into ordering a dataframe based on a certain group id. This could be used in the real world, for example, to list the best selling products from various brands. Note that to begin with, there could be alternative ways to proceed. One could use Cassandra tables clustering keys and paging to navigate the products by brand and have the products stored in order on disk. This would potentially mean replicating the skews on the disk, and not being able to index the products by id in order to jump to a specific page, as the paging can only start from the beginning of the products if you don't have an incremental id saved within the tables.
So now let's imagine that all brands have a relatively low number of products, except a few which have many millions. We also order the dataframe and give rows an index over a window in this fashion:
def orderProductsBy(
products: Dataset[ProductsForOrdering],
colname: String,
): Dataset[ProductsForOrdering] = {
val window = Window.partitionBy("brand_id").orderBy(col(colname).desc)
products
.withColumn("ordering", row_number().over(window))
.as[ProductsForOrdering]
}
A problem will arise where one tasks will take much longer than others, which will leave CPUs idle for most of the ordering time.
A potential solution
A common solution to this problem is to treat the skewed data separately. That's what we will set to do. We will filter the products based on how many the brand has, treat the vast majority of brands with the same function as above, and give the handfull of brands with a large number of products a special treatment which will allow for their ordering to be spread over multiple tasks and thus multiple cores. For efficency purpose, we will also salt the columns when partitioning by brands in order to be able to both filter quickly (as we will filter on partition key) and have smaller balanced data partitions. All that, except separating large cluster that I will leave to you, is done the following way:
def orderProductsIndividually(
productPreparedForOrdering: Dataset[ProductsForOrdering],
colname: String
): Dataset[ProductsForOrdering] = {
// number of subdivisions of each brand partition
val evilDataParallelism = 4000
val saltedBrandProducts = productPreparedForOrdering
.withColumn("salt", (rand * evilDataParallelism).cast(IntegerType))
.repartition(col("brand_id"), col("salt"))
.persist()
// as saltedBrandProducts is used in the execution plan that collect largeBrands
// and the one for the code below, we should save some time by persisting it.
// we collect the list of large brands for iterating with a foreach
val largeBrands =
saltedBrandProducts.select("brand_id").distinct().collect().map {
case row: Row => row.getInt(0)
}
var resultDataset = spark.emptyDataset[ProductsForOrdering]
// for each brand, we append a union of its ordered products
// to the spark processing plan
uniqueClusters.foreach { bid =>
resultDataset = resultDataset.union(saltedBrandProducts
.filter(col("brand_id") === bid)
.orderBy(col(colname))
.as[ProductsForOrdering]
.rdd
.zipWithIndex
.map { case (row, index) =>
row.copy(ordering=(index+1))
}
.toDS()
.as[ProductsForOrdering])
}
// let's not forget to unpersist this dataset as it won't be used again
saltedClustAddrs.unpersist()
resultDataset
}
Try not to apply this special treatment to too many or too small groups as it will then make little sense due to this foreach and to the potentially weak CPU gain.
Conclusion
Applying this strategy to highly skewed datasets translated into a nice performance and stability boost for our spark jobs. Nonetheless, it is not a silver bullet as it only addresses severe skews.
Spread the word
Thank you for reading. If you liked this article, feel free to share it on LinkedIn, send it to your friends, or review it. You are also welcome to report any error, share your feedback or drop a message to say hi.